论文学习:Encrypted Malware Traffic Detection via Graph-based Network Analysis
中文题目:基于图的网络分析加密恶意软件流量检测
发表会议:RAID 2022: 25th International Symposium on Research in Attacks, Intrusions and Defenses
发表年份:2022-10-26
作者:Zhuoqun Fu, Mingxuan Liu, Yue Qin, Jia Zhang, Yuan Zou1, Qilei Yin, Qi Li, Haixin Duan
文章概述
近年来,攻击者利用加密协议和规避技术隐藏 URL 负载、HTTP 头等信息,给传统的基于网络流量的恶意软件检测技术(如 DPI)带来了挑战。为此,研究人员利用机器学习/深度学习方法,处理 TLS 流量统计值、关联设备、域名等信息,构建智能检测方案。但现有方法依赖专家经验,而且没有充分挖掘场景信息。
一些规避技术举例:1)加密协议下通信载荷不可见;2)改变从主机到 C&C 服务器的访问频率,例如可以在固定的心跳包上加入 jitter;3)使用良性软件的连接,使用良性第三方网站作为初始访问点,减少网站访问数量等。
另外,网络用户数量增加、网络吞吐量增大、网络连接变复杂、检测中需要综合考虑的特征维度增多等因素,都加大了计算复杂度。
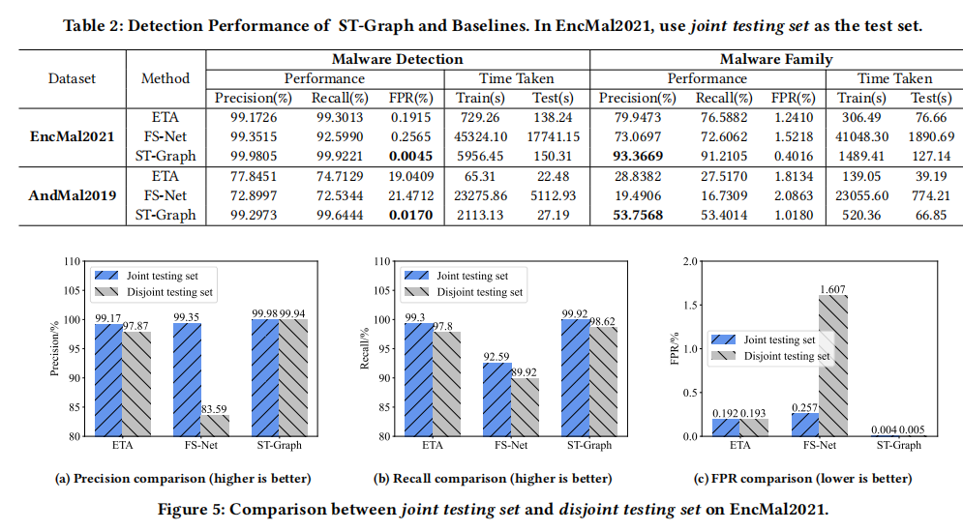
因此,实际网络场景中要求检测方法具有高准确性和高效率。本文提出 ST-Graph,综合考虑常用的流量属性以及空间(spatial)和时间(temporal)特性实现加密场景下的恶意流量实时检测。作者在两个数据集上进行实验评估,均达到了 99% 以上的准确率和召回率,而且误报率比基线模型低了两个数量级。另外,作者还将 ST-Graph 在两个真实网络场景中部署了一年左右,1.7Gbps 的带宽下,仅需 160s 就可以处理完 5 分钟的流量检测。
研究动机
作者随机采样 30 个(主要面向远程控制类)恶意软件样本,沙箱运行发现,在代码方面,(也许是为了节省成本)同一家族的恶意软件更喜欢共享相似的软件框架,因此也具有相似的流量模式;2)恶意软件通常不及时更新,往往会接受低版本的 TLS 连接;3)恶意软件开发者通常使用默认的固定参数,比如通常将与 C&C 连接的时间间隔设置为 60s。
解密相关流量发现,在流量行为方面,由于存在明确的联合攻击目标,远程控制攻击具有相对固定的流量模式。在攻击阶段,通过欺诈网站或漏洞安装恶意软件至受害者机器。在控制阶段,受感染主机连接到 C&C 服务器以接受并执行指令。恶意软件通常喜欢在不同阶段连接不同的目标服务器,因此形成了连接次序。另外,恶意软件经常通过伪造正常连接来测试当前网络情况,比如主动查询主机的共有 IP 或下载服务器的证书等。
总的来说,恶意软件产生的流量具有两方面特征:
- 空间特征指主机和目标服务器之间的访问聚集性,比如同一家族中某些恶意软件在框架上进行重用,不同的受感染主机也会集中地访问相同的一组恶意控制服务器,流量行为高度一致。
- 时间特征指可以通过一段时间内的主机连接顺序重建恶意软件感染过程;而且由于固定参数的设置,受害主机和控制服务器之间的通信是有规律的,尤其是在数据包长度和发送间隔上。
论文方法
ST-Graph 位于网关处,检测内部主机向外访问的加密流量,发现组织内部受感染的主机。
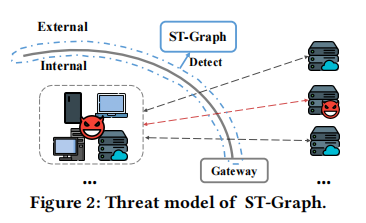
ST-Graph 将主机网络行为的空间(即主机和服务器之间的访问)和时间(即连接顺序和时间相关信息)特征整合到主机表示中,以提高检测决策的有效性。本方案由 3 个部分组成,即流量预处理器、图表示器和检测器。
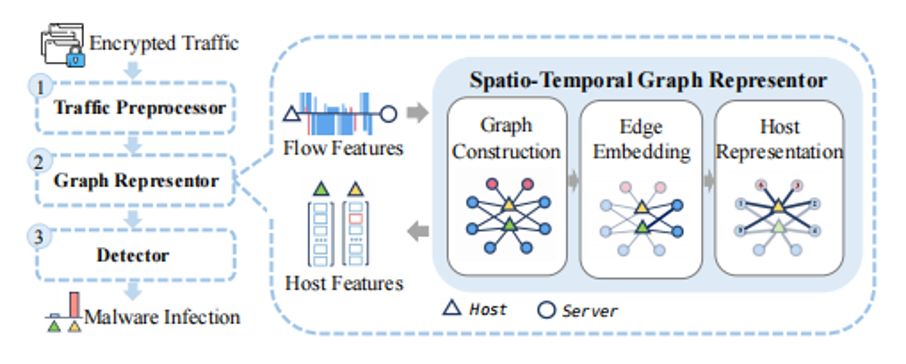
输入数据为原始流量 pcap 包,经过流量预处理器进行流重组,恢复完整的通信过程。具体来讲,从每个原始数据包中提取五元组<源 IP,源端口,目的 IP,目的端口,协议>。同一五元组关联的数据包集合成流,之后,分析 TLS 握手过程来提取每个流中的关键信息(如 TLS 版本、密码套件、数据包数、字节数等)。
基于上述信息,图表示器构建异构图反映主机和服务器之间的端到端通信。设计图节点嵌入算法完成主机的向量表征。最终检测器使用随机森林预测每台主机的被感染风险值,输出可疑主机列表及其访问信息。
下面介绍核心算法:
首先做一些记号约定:
- 图 $G=(H,D,E,S,I)$
- 顶点集合 $H$:内部主机,用 IP 初始化。
- 顶点集合 $D$:外部服务器,用域名 (SNI) 或 IP 地址初始化。
- 边集:$E = {e \mid e = (h_e, d_e), h_e \in H, d_e \in D}$ 主机和服务器之间的所有连接。如果主机 $h$ 与服务器 $d$ 进行 TLS 握手,则连接这两个节点的边 $e = (h,d)$ 添加到 $E$ 中。
- 时间特征 $I$: 每条边 $e$ 的时间顺序 $i_e$,表示其宿主 $h_e$ 连接该边 $e$ 的顺序。
- 流属性 $S$: 每条边 $e$ 对应的流量特征,包括 TLS 握手特征,域名(DGA 识别),在流中发送和接收数据包的数量、长度或时间间隔等等。
边嵌入
再给出一些声明:
- 随机游走走过的边集记录为:$N_e$
- 边 $e$ 的邻边集合记为 $C_e$,公式为 $C_e = {u : (h_u, d_u) \mid u \in E, h_e = h_u \text{ 或 } d_e = d_u}$,直观理解就是对于边 $e$ 而言,所有的和它共有节点的边。
- 两条边 $u, v$ 直接距离 $d$ 为 $d(u, v) = \lvert i_u - i_v \rvert$,注意这里算的都是主机的连接顺序。
通过随机游走来收集 $N_e$: 对于初始边:假设从边 $o$ 出发,该边的相邻边集合为 $C_o$,则走向下一个边 $x$ 的概率为:
\[\text{Pr}(w_1 = x \mid w_0 = o) = \frac{\frac{1}{d(o,x)}}{\sum_{y \in C_o} \frac{1}{d(y,o)}}\]即倾向于选择与当前边连接顺序距离最小的边作为下一步。 对于中间边:除了要找距离最小的边,还要控制返回上一个边的概率。上一个边为 $u$,当前边为 $v$,下一个边为 $x$ 的概率为:
\[\text{Pr}(w_{i+1} = x \mid w_i = v, w_{i-1} = u) = \frac{\alpha_{u,x} \cdot \frac{1}{d(v,x)}}{\sum_{t \in C_v} \alpha_{u,t} \cdot \frac{1}{d(v,t)}}\] \[\alpha_{u,x} = \begin{cases} 1/p, & x == u \\ 1, & x \text{是} u \text{的一个近邻时} \\ 1/q, & \text{其他} \end{cases}\]$p$:用来控制从 $v$ 回到起点 $u$ 的概率。 $q$:用来控制 $v$ 去到新节点的概率。当 $q < 1$ 时,倾向于访问全局节点 (DFS);如果 $q > 1$,倾向于访问本地节点 (BFS),这增强了对周围邻居的覆盖。
为了将图的空间和时间特征合并到边嵌入中,为每条边设置一个向量 $r_e$,则边 $u$ 和边 $n$ 相关的可能性计算公式为:
\[\text{Pr}(n \mid u) = \frac{\exp(r_u \cdot r_n)}{\sum_{v \in E} \exp(r_u \cdot r_v)}\]假设不同边对之间的邻域关系是独立的,并进一步定义边 $u$ 的邻域似然为: $\text{Pr}(\mathcal{N}_u \mid u) = \prod_{n \in \mathcal{N}_u} \text{Pr}(n \mid u).$
通过最大化边 $u$ 及其网络邻域 $N_e$ 内所有边之间的相似性来优化每条边的时空嵌入向量,其实就是让那些在“时空”上是邻居的边,它们的“画像”在数学上也必须尽可能相似。即:
\[\begin{aligned} \max_{r_u} \prod_{u \in E} \text{Pr}(\mathcal{N}_u \mid u) &= \max_{r_u} \sum_{u \in E} \sum_{n \in \mathcal{N}_u} \log \frac{\exp(r_u \cdot r_n)}{\sum_{v \in E} \exp(r_v \cdot r_u)} \\ &= \max_{r_u} \sum_{u \in E} \left[ -|\mathcal{N}_u| \cdot \log Z_u + \sum_{n \in \mathcal{N}_u} r_u \cdot r_n \right] \end{aligned}\] \[Z_u = \sum_{v \in E} \exp(r_v \cdot r_u) \text{ is a normalization factor.}\]再使用随机梯度上升和负采样的方法进行优化。 最后的边嵌入 $f_e$,拼接流属性 $s_e$ 和 $r_e$,即 $f_e = \phi([s_e \parallel r_e]), \text{ where } \phi(x) = x / \lVert x \rVert$。
主机表示
在网络中,每台主机可能访问许多公共服务来获取大量流量数据,这对于描述主机的行为并不是很有信息量。因此,我们根据在信息传播之前通过流访问的服务器的重要性对与主机关联的流进行排名:
- 所有主机 $H$ 访问该服务器的频率
- 主机 $t$ 访问服务器 $u$ 的顺序 $(i_e : e \in E, h_e = t \wedge d_e = u)$
直观地说,如果一个服务器 $u$ 被大多数主机访问,那么它很可能也会被目标主机 $t$ 访问;如果 $t$ 在早期的阶段访问 $u$ ,则 $u$ 对于 $t$ 是一个重要的服务器。 由此定义出边 $e$ 对它的主机 $t$ 的重要性公式如下:
\[\rho(e) = \frac{\lvert \{e' \mid e' \in E \wedge d_{e'} = u\}\rvert}{i_e \cdot |E|},\]其中 $e’$ 是所有结束于服务器 $u$ 的边的数量,$\lvert E \rvert$ 是边的总数。
再设主机 $t$ 和边 $e$ 的相关评分为:
\[\text{corr}(t, e) = \lambda \rho(e) + (1-\lambda) \frac{\exp(g_t \cdot f_e)}{Z}\] \[Z = \sum_{i \in E} \exp(g_t \cdot f_i)\]$g_t$ 即为最终要求的主机表示,这个评分结合了边的重要性 $\rho(e)$ 和宿主表示 $g_t$ 与边嵌入 $f_e$ 的相似性。 再设 $\mathcal{L}_t$ 为所有从主机 $t$ 发出的边,$\mathcal{L}_t$ 中所有边的联合相关评分定义为:
\[\text{CORR}(\mathcal{L}_t) = \prod_{e \in \mathcal{L}_t} \text{corr}(t, e) = \prod_{e \in \mathcal{L}_t} \left[ \lambda \rho(e) + (1-\lambda) \frac{\exp(g_t \cdot f_e)}{Z} \right]\]对数形式经过泰勒一阶展开近似为:
\[\begin{aligned} \log [\text{CORR}(\mathcal{L}_t)] &= \sum_{e \in \mathcal{L}_t} \log \left[ \lambda \rho(e) + (1-\lambda) \frac{\exp(g_t \cdot f_e)}{Z} \right] \\ &\approx \left[ \sum_{e \in \mathcal{L}_t} \left( \log(\lambda[\rho(e) + \xi]) + \frac{\xi}{\rho(e) + \xi} \right) \cdot f_e \right] \cdot g_t \end{aligned}\]定义 $M_t$ 为:
\[M_t = \left[ \sum_{e \in \mathcal{L}_t} \left( \log(\lambda[\rho(e) + \xi]) + \frac{\xi}{\rho(e) + \xi} \right) \cdot f_e \right]\]则
\[\log[\text{CORR}(\mathcal{L}_t)] \approx M_t \cdot g_t\]若想最大化 CORR,则需要两个向量同向。 再规定 $g_t$ 为单位向量,则最优主机表示可求得:
\[g_t^* = \frac{M_t}{\lVert M_t \rVert}\]小总结
ST-Graph 会构建一个属性异构图来捕捉加密流量中的时空行为。
- 使用一种“区间倾斜随机游走”算法来学习“时空嵌入” $r_e$,这个嵌入画像既编码了“空间”上的邻居关系,也编码了“时间” 上的连接顺序。
- 将这个学到的 $r_e$ 与“流属性” $s_e$(如 TLS 握手、域名特征、统计特征等等)拼接起来,形成一个完整的“边画像” $f_e$。
- 最后,通过一个高效的“闭式解”,融合主机所有关联边的“边画像” $f_e$ 及其重要性,计算得到最终的“主机画像” $g_t$。
实验
实验涵盖两个任务:恶意软件检测和恶意软件家族分类。第一个任务用于区分恶意网络行为主机和良性主机,第二个任务则进一步识别恶意软件所属的具体家族。
数据集
公开数据集 CICInvesAndMal2019,包括 5065 个良性和 426 个恶意(39 个家族)安卓应用,在真实智能设备上生成的流量和设备日志。
私有数据集 EncMal2021,通过捕获恶意样本流量和校园网流量构建:
- 恶意流量: 沙盒运行 53,111 个样本 (239,007 条流),包含 39 个恶意软件家族。
- 良性流量: 校园网流量 (Alexa Top 1M 过滤,匿名化 IP) 和沙盒运行良性样本流量。
实验结果
恶意软件检测
决策边界:

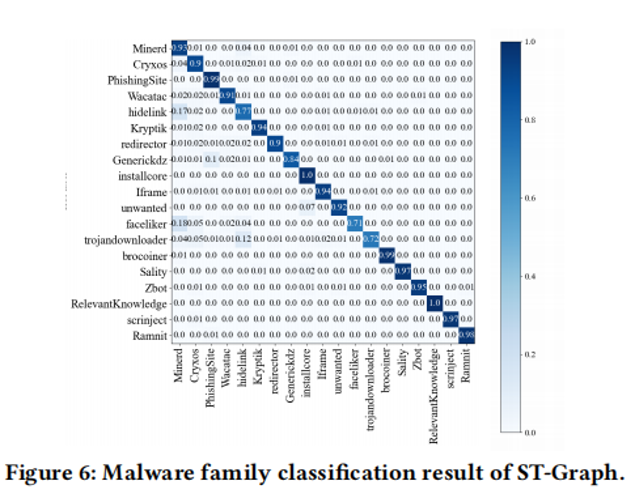
主机被哪种家族感染
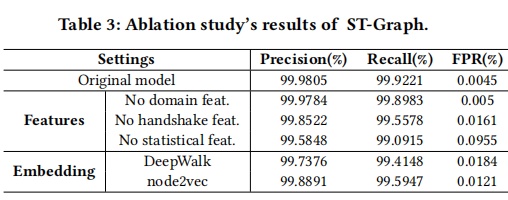
泛化能力
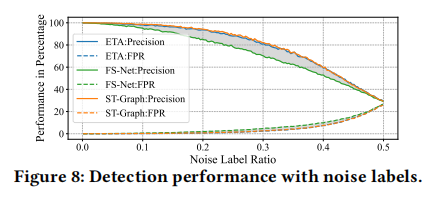
鲁棒性测试
增加噪声标签
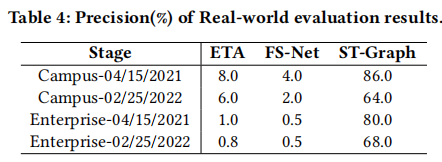
真实世界评估
在校园网和企业网关部署了近一年的时间。这两个网络场景中都有上万活跃用户,网络吞吐量大(校园网为 3.6Gbps,企业网为 1.7Gbps),足以体现 ST-Graph 的效率。
随机选择模型的 50 个告警进行人工分析。比如,如果目标服务器的 IP 地址、域名等标识出现在威胁情报中,则表示告警正确。否则,会手动访问该目标服务器,并根据响应内容进行判断。